当网络刚刚出现
当人们刚想到让两台计算机通信,模型是这样的:
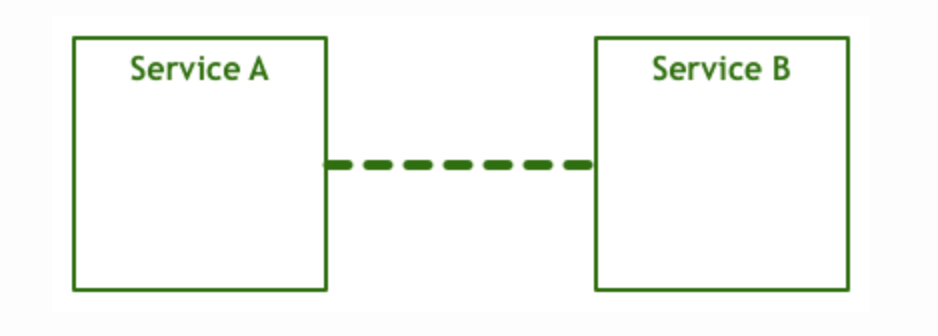
但上面过于简单的建模,无法使任意两台计算机之间的通信变得通用。分层的网络协议,使应用之间的通信时,应用本身不用关心网络的底层细节,例如如何拆包粘包,如何将字节序列转化成电信号等等。
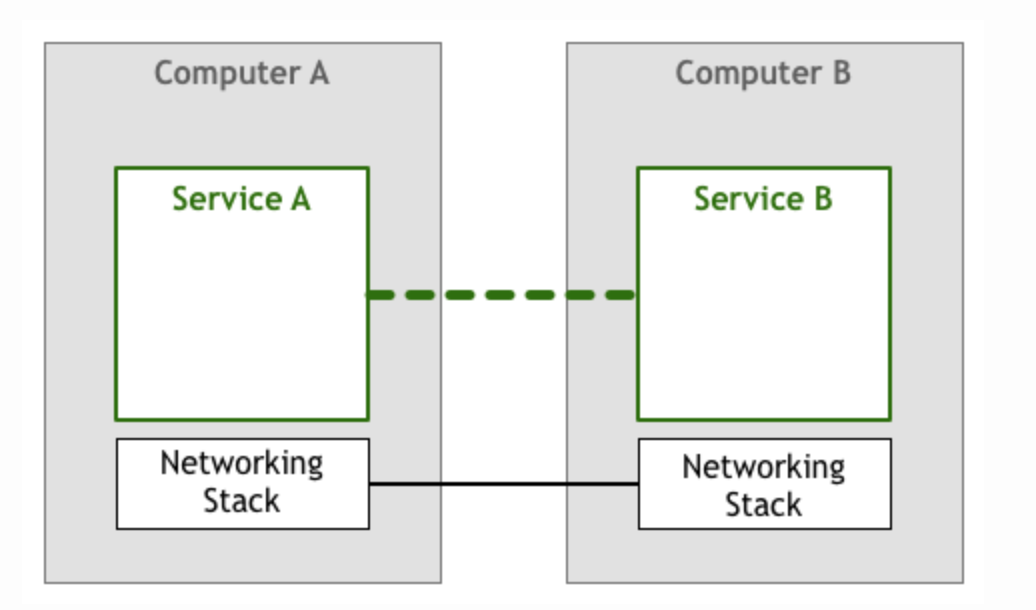
上面的模型依然存在问题,因为应用A在向B发送请求和数据包时,并不知道B是否能处理过来,如果B不能及时处理网络包,则会丢失数据。因此应用除了业务逻辑之外,还需要有专门的模块控制数据包的发送速度。
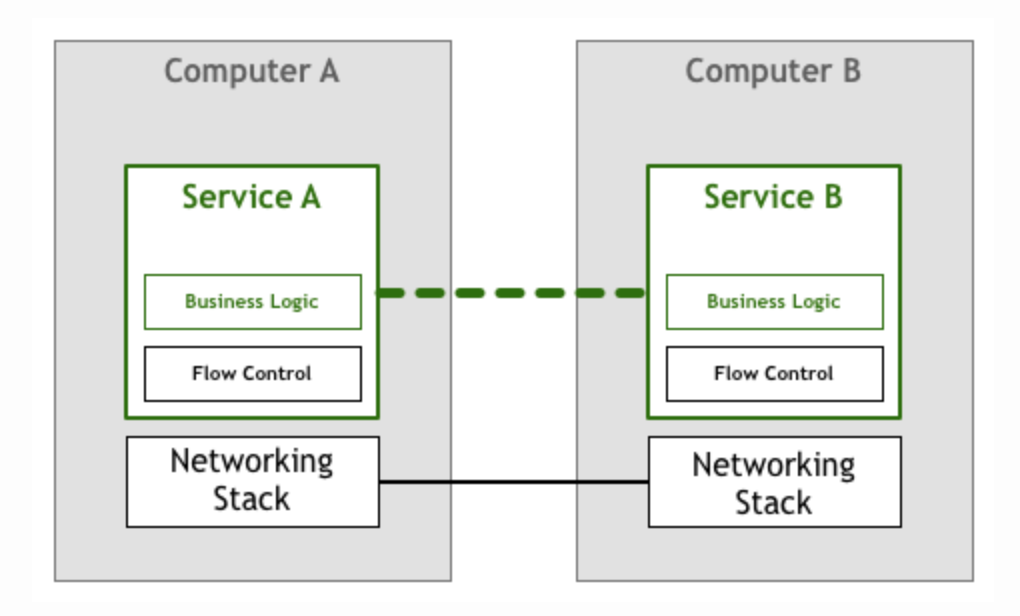
幸运的是TCP/IP传输层协议的出现,从底层解决了流量控制和拥塞避免的问题,实现了可靠传输。
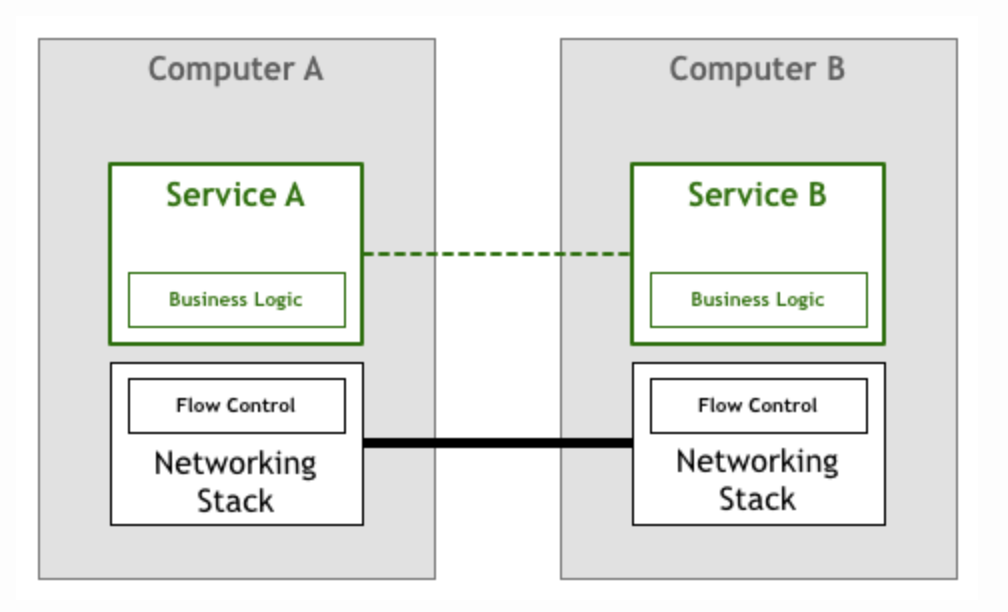
上面的模型也成功的沿用了很长一段时间。
微服务出现
随后计算机逐渐变得便宜,出现了更多的节点和更可靠的网络连接。业界开始使用各种类型的网络系统,出现了更细粒度的分布式agent和面向服务的体系架构(SOA,Service Oriented Architectures)但依旧较重的服务组件。
90年代,Peter Deutsch和他的同事共同提出了有关分布式系统的8条错误假设(The 8 Fallacies of Distributed Computing):
- 网络是可靠的
- 没有延迟
- 带宽无限大
- 网络是安全的
- 网络拓扑不会改变
- 只有一个管理员
- 传输成本是0
- 网络是同构的
这8条谬误,是为了提醒分布式系统的工程师们,不能简单忽视上面的问题,需要显式的处理它们。在分布式系统或者说微服务框架体系下,我们至少需要做以下事情:
- 快速配置计算资源
- 基本的监控系统
- 快速的部署
- 易于配置的存储系统
- 轻松的访问边缘节点
- 权限验证和授权
- 标准RPC协议
虽然TCP/IP协议和和通用的网络模型,仍然起到了很大的作用,但现如今,更智能的微服务架构模型需要新的服务层。例如服务发现(Service Discovery)和断路器(Circuit Breaker)。
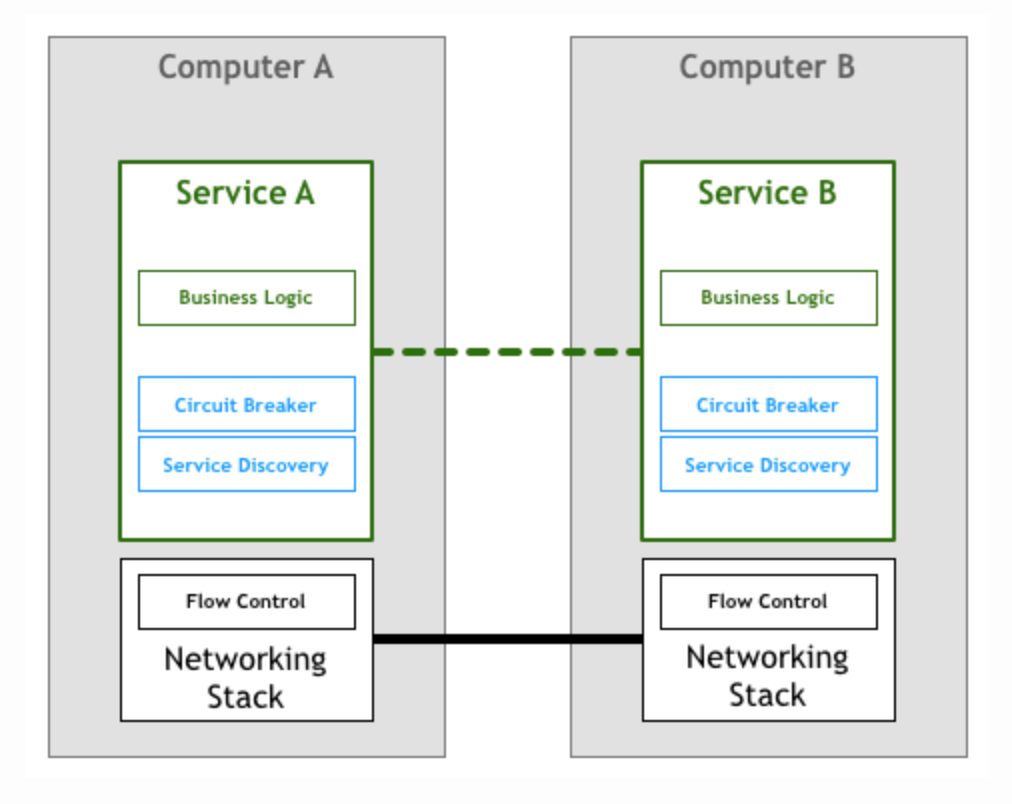
The basic idea behind the circuit breaker is very simple. You wrap a protected function call in a circuit breaker object, which monitors for failures. Once the failures reach a certain threshold, the circuit breaker trips, and all further calls to the circuit breaker return with an error, without the protected call being made at all. Usually you’ll also want some kind of monitor alert if the circuit breaker trips.
像断路器这样的简单装置,可以为服务之间的交互提供可靠性保证。(个人使用过Netflix公司的Hystrix)即便如此,随着分布式系统规模的增长,某个组件出问题的可能性也成指数级增加。在一个庞大系统中的某个组件出问题,可能导致其客户端以及客户端的客户端相继发生断路。
在过去需要几行代码搞定的东西,现在需要在各个client端重复模板代码来处理断路逻辑
如果你使用过Hystrix,则你一定知道,你的代码中将大量包含类似:
1 | public class CommandMayFailure extends HystrixCommand<String> { |
这些样板代码往往需要设置线程池大小,断路器的失败阈值,超时时间,失败时的fallback逻辑等等。他们会遍布整个分布式系统的每个服务,他们与主要业务逻辑无关,大部分都是相同的。是不是很烦?
实际上,Facebook的Proxygen和Twitter的Finagle这样的类库,意在避免这样的模板代码。
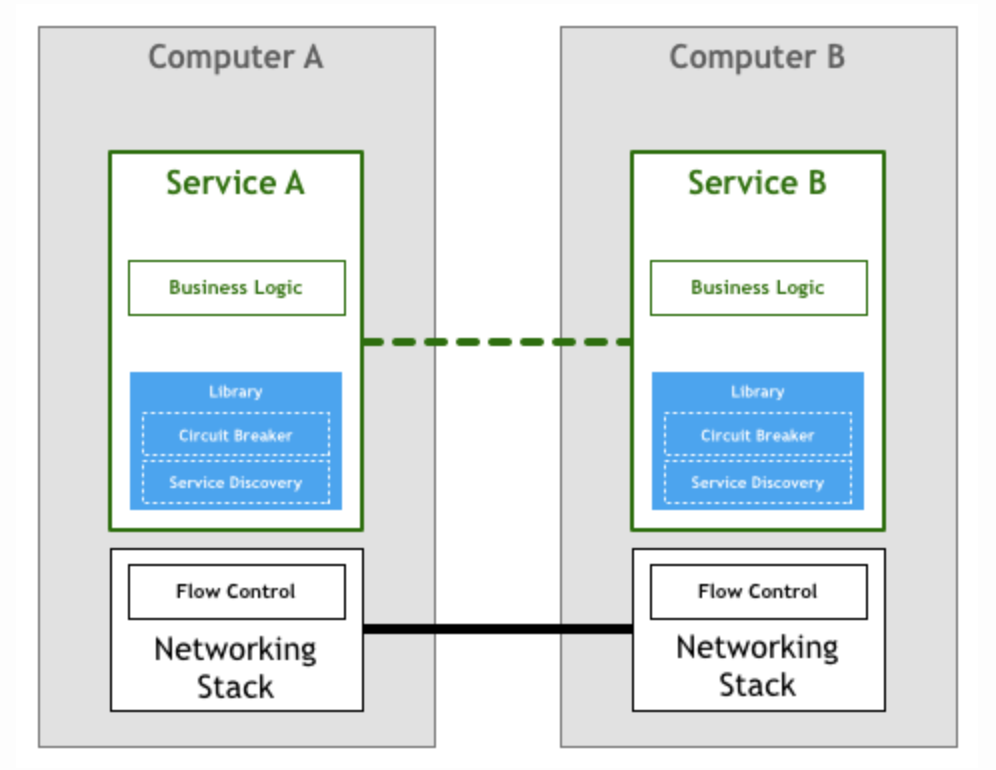
上图描述了像Netflix、SoundCloud、Twitter这样的微服务先驱的微服务架构。
把断路器和服务发现下沉到类库中,有以下几个缺点:
- 团队需要有专门的人力和时间,为适配这种类库构建生态系统
- 类库限制了你在微服务中使用什么样的工具、运行时环境和开发语言
- 在庞大分布式系统中,使用上述类库模型,类库本身也需要维护,版本适配将非常复杂。
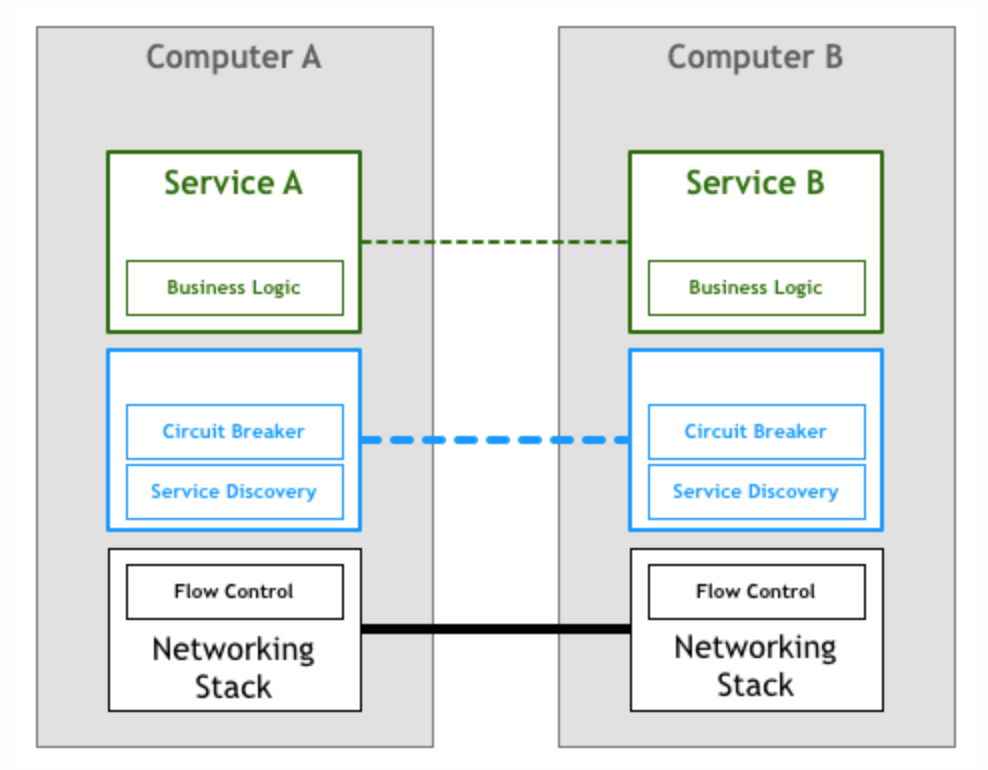
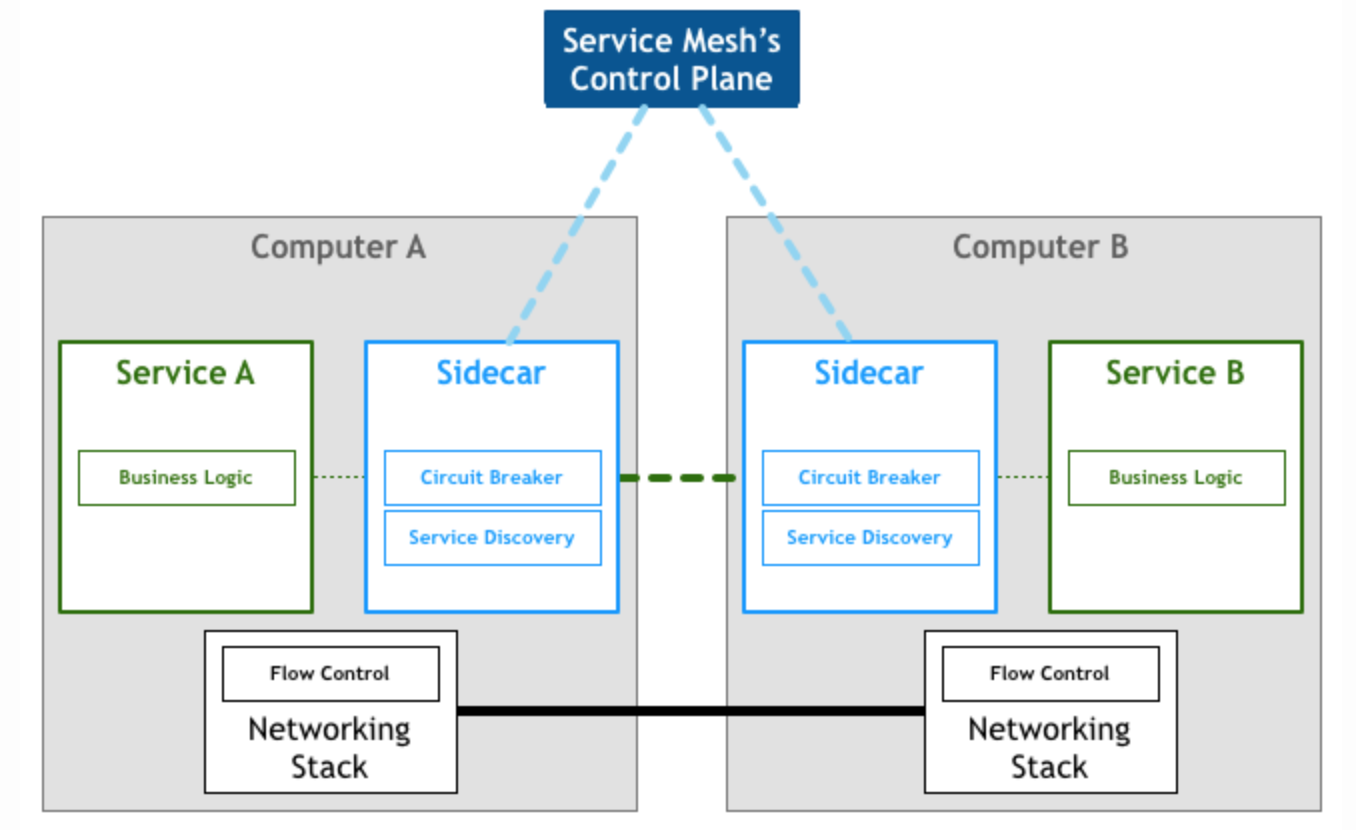
Sidecar
对比分层的网络协议栈,我们更希望断路和服务发现作为一个服务层(如下图所示),屏蔽底层的逻辑,对应用透明。但更改网络协议栈短期内是没有可能的事情。
有些将这个服务层实现成一个代理应用(Proxy),服务之间不直接相互调用,而是将流量直接打到代理上,由代理做服务发现和路由。
这里衍生出的一个重要概念,就是Sidecars。Sidecar是和主应用进程相伴运行的进程,用来为主应用进程提供额外的功能特性。这里可以参见AirBnb和Netflix的两篇有关Sidecar的文章。
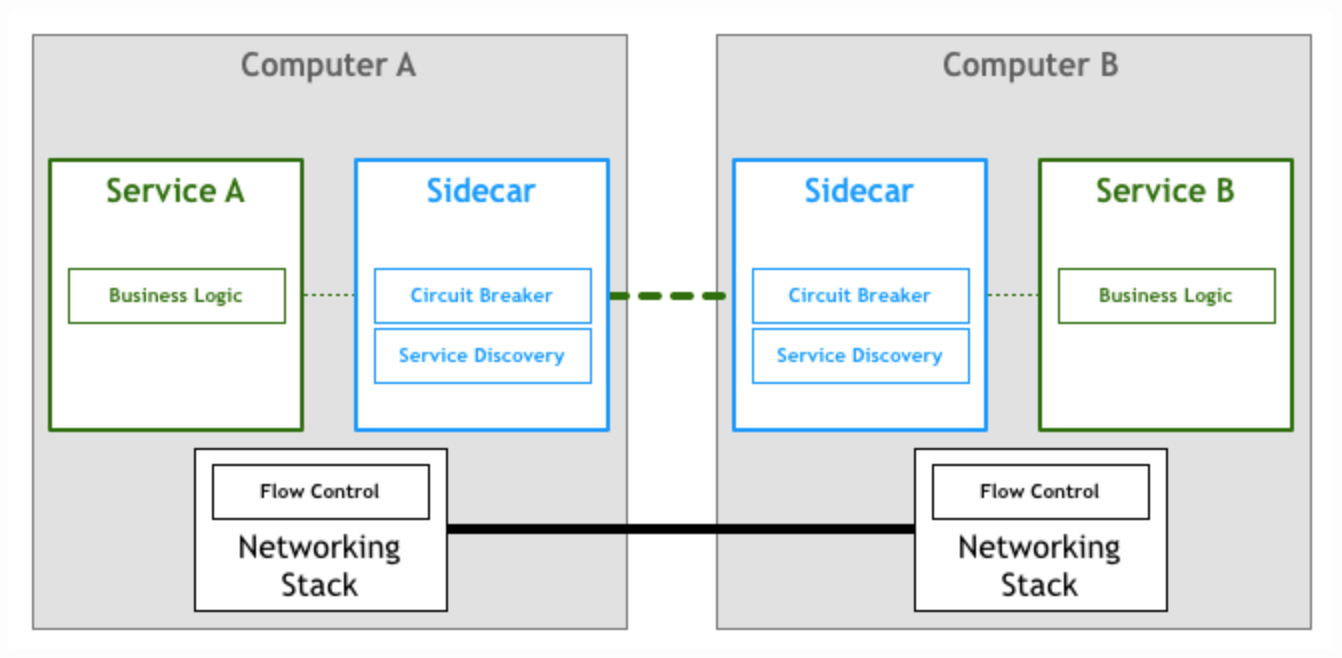
Service Mesh
如果你的微服务系统中各个应用间通过Sidecar proxy相互调用,则你的部署图可能是下图这样的:
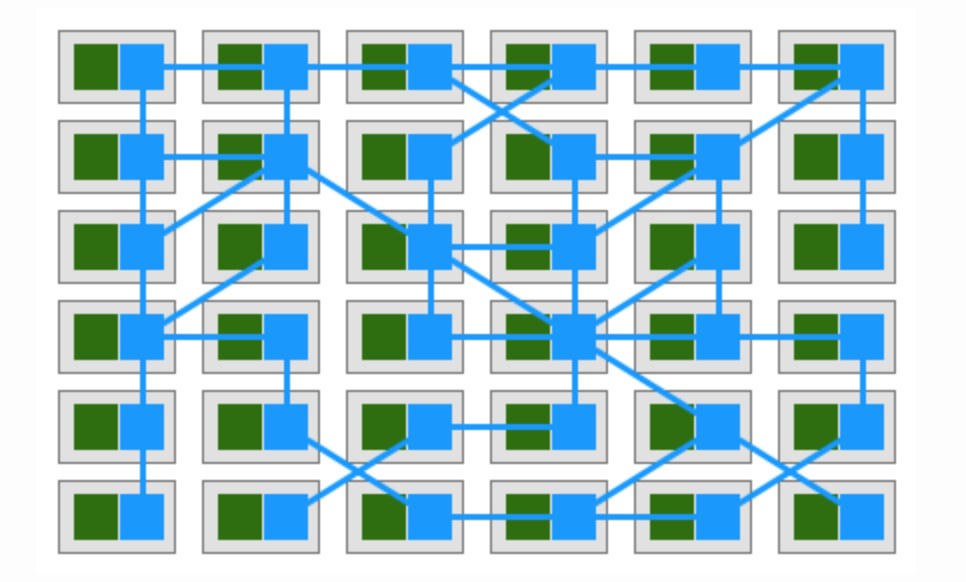
2017年William在文章中这样定义Service Mesh:
A service mesh is a dedicated infrastructure layer for handling service-to-service communication. It’s responsible for the reliable delivery of requests through the complex topology of services that comprise a modern, cloud native application. In practice, the service mesh is typically implemented as an array of lightweight network proxies that are deployed alongside application code, without the application needing to be aware.
而这套机制,已经在先进的PaaS运行时环境Kubernetes和Mesos完美支持:
最近火爆的项目Istio project则是Service Mesh系统的重要实例。
参考
- http://philcalcado.com/2017/08/03/pattern_service_mesh.html
- https://en.wikipedia.org/wiki/Fallacies_of_distributed_computing
- https://martinfowler.com/bliki/CircuitBreaker.html
- https://github.com/Netflix/Hystrix
- https://code.fb.com/networking-traffic/introducing-proxygen-facebook-s-c-http-framework/
- https://finagle.github.io/blog/
- https://medium.com/airbnb-engineering/smartstack-service-discovery-in-the-cloud-4b8a080de619
- https://medium.com/netflix-techblog/prana-a-sidecar-for-your-netflix-paas-based-applications-and-services-258a5790a015
- https://istio.io/